Architecture
- Former user (Deleted)
Library first
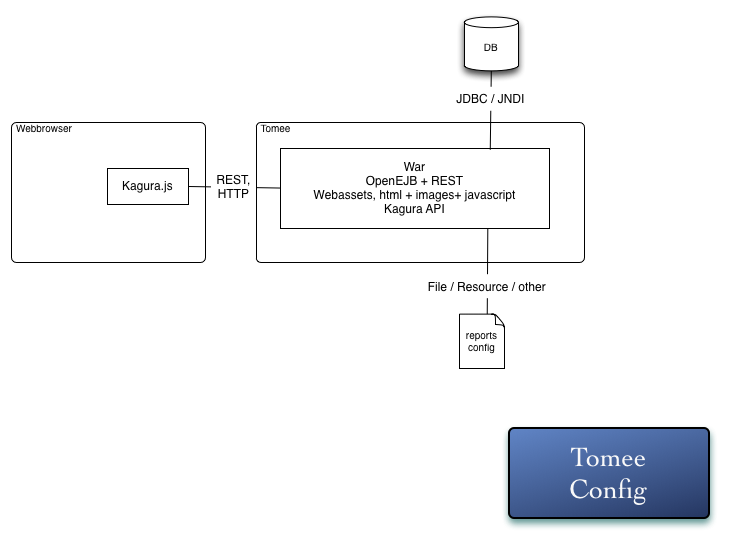
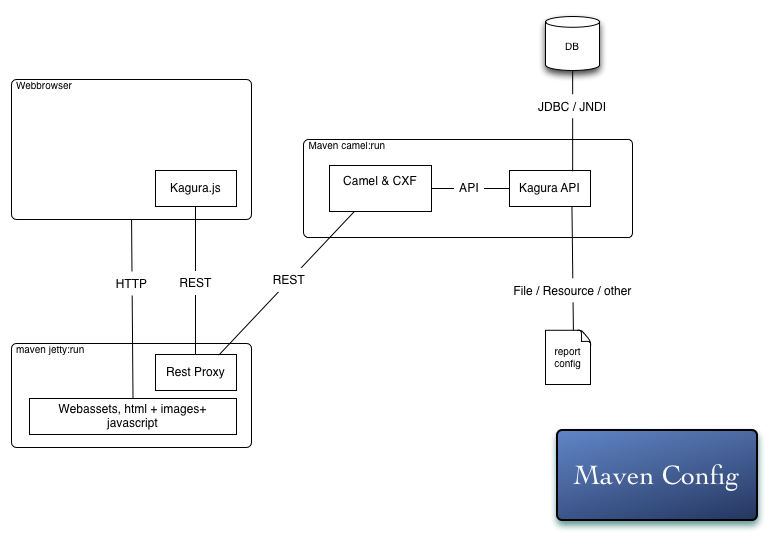
Kagura is a library first. Which means it was designed to be modular and self contained. It also provides minimal constraints in the way that you can use it, and is intended to be embedded into a larger scale application, such as some of the example components demonstrate. Kagura is designed to be simple in the way you can use it. Many of the components provided inside the core of kagura are optional and provided as helps, examples or guidelines regarding the architecture you can make. Below are two production ready architecture diagrams, and one development architecture. All which work out of the box:
The Karaf / Camel configuration, the Kagura API is deployed as it's own bundle.
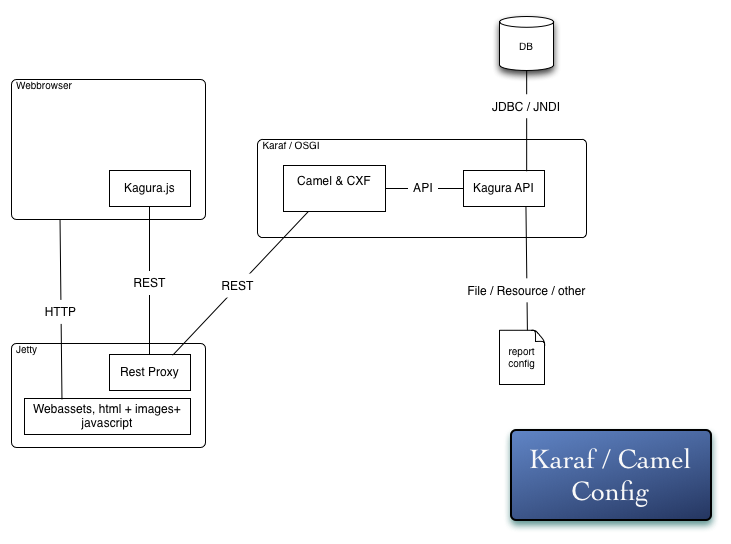
The War file configuration: (Using rest, you can also use JSF.)
When developing you may want a quick version to start while you edit, during that you can use the maven configuration;
If you are not interested in taking advantage of OSGI, I would recommend sticking to the WAR configuration.
Components
The components that make up the current (as of writing) Kagura source tree:
- Kagura API / report-core
- Karaf
- Camel / CXF routes
- Assembly
- Features
- Example-Authrest
- Javascript / Jetty
- Resources
- Rest-API
More on each component below:
Kagura API / Report Core
This is the heart of the program where all the major functionality takes place. It has several components to it:
- Core components
- Storage Providers
- Parameter Types
- Connectors
- Freemarker
- Configuration Model
- Helper components
- Authentication Providers & Model
- Export Handler
The Rest-API component technically belongs in Helper components but it is separated to avoid increasing the dependencies of the reporting-core, and it's provided as a guideline only.
Core components
The core components are components which it would be hard to use Kagura without, and it isn't recommended to do so. They are all components essential in providing the basic functionality of reports to end users. (Which is the aim of Kagura.)
The components are as follows:
Storage Providers
You are required to use one report provider when you use Kagura in the "typical" sense. Storage providers simply put, the component which lists, and provides the report configuration for the rest of the application. As of writing there are 3 main ones:
- File Report Provider
- Super File Report Provider
- Cached Report Provider
Other possible report storage engines which I would like to see:
- Tar (ziped / gzip / bzip'd?) Report Provider
- Git Report Provider (I did have one, but I disabled it as it required physical disk space.)
- S3 Report Provider
- DB Report Provider
- NoSQL Report Provider (Design had this in mind.)
- REST Report Provider
Note, Kagura does not preform any write operations to the disk.
The File Report Provider, expects to see a layout such as this:
- <report1name directory>
- reportconf.yaml
- <report2name directory>
- reportconf.yaml
And so forth.
Super File Report, is essentially a "one file" version of the above. So it uses a single YAML file for all the reports.
Cached Report Provider, you actually specify a different report provider and it will cache the report configuration.
Parameter Types
Parameter types allow for a mapping of Report Parameters to native Java data types. The names of the parameters are also used by Kagura.js to determine what type of value the parameter is expecting. However you can use "extraOptions" instead. Some examples of types are:
| Parameter Type | Java Type |
|---|---|
| BooleanParamConfig | Boolean |
| DateParamConfig | Date (yyyy/mm/dd only) |
| DateTimeParamConfig | Date |
| MultiParamConfig | List<?> |
| SingleParamConfig | String |
Kagura uses PropertyUtils from the Apache Commons Beans Library to map values in to this. Kagura also installs in some circumstances the two converters into "ConvertUtils" dateUtils: "yyyy-MM-dd", "yyyy-MM-dd hh:mm:ss" (See ISO8601.)
Parameters such as a Combo and Listbox (Single selection and multi selection) allow "Datasources" for the list of options these data sources can be:
- A plain old list
- A Groovy script
- A SQL script (a sub-report.)
Connectors & Freemarker
Connectors are the components which allow you to specify the data source for a report. In some of the reports Kagura uses Freemarker as a macro driver. There are 4 data sources for reports.:
- Fake
- Groovy
- JDBC & Freemarker
- JNDI & Freemarker
Like all Kagura components, if you were to crack open the source, you would find that the components are rather lite weight.
Fake, simply allows you to build in the data into the application as a list of hashtables. It has a VERY limited capacity for filtering parameters. This specifically exists for the purpose of demos.
Groovy, allows you to use a Groovy script to produce the desired output, this can be used for a demo, or it can be used to connect to a unique data source, or summarise information.
JDBC / JNDI, these are standard SQL scripts that are executed safely using the prepareStatement provided you use the Freemarker pre-processor correctly. The preprocessor allows for much greater flexibility over the standard query mechanisms, and is required to apply parameters to the system.
Configuration Model
This is where the configuration is "stored" in memory. It used to deserialize the YAML and is partially passed up the chain (such as eventually to Kagura.js)
Helper Components
The "helper" components are there to provide additional functionality.
The "Export Handler"
Is a useful API for turning Kagura output in to reports, CVS, PDF or Excel documents. It's simple and easily substitutable.
Authentication Providers & Model
Kagura provides model and sample and simple mechanisms for providing user and group information to the middleware. Kagura does not do any user and password validation itself. These are provided as sample only. In a production environment please consider using a different authentication method. Such as JAAS.
Karaf
Camel / CXF routes Bundle
This component provides the REST front end and the Authentication for the Karaf based middleware. It uses the REST definition provided by Rest-API (documented in a later chapter.) Then uses CXF and Camel, to route the contents to various beans to carry out the business logic and API calls. To allow for configuration via the configuration files in the assembly, we also inherit the Authentication Providers and Storage Providers in such away to allow them to be beans inside the Spring container, and have their properties auto populated by Spring.
The operations is simple, first check or provide authentication, then route the calls to the correct bean function to get the desired value.
Assembly
This builds a zip or tar.gz that contains a complete fully functional setup for the REST component. Inside you will find some example reports in etc/reports as well as all the configuration you need in etc. It also builds a development version, which you can run in the target directory and it's configuration files are configured to point to the reports in the source, rather than in the build directory. This can speed up development efforts.
Features
This generates and installs the pom and features file into maven. Which is required to correctly import all the resources into an OSGI container.
Example Authrest
This is an example authentication provider for REST. Essentially there is a RestAuthenticationProvider, which offloads the authentication process to a rest end point. This is an example implementation of the end point.
Javascript / Jetty
This is where the example HTML, CSS and Javascript live. You can find Kagura.js here which is a javascript file which handles does the jQuery/ajax work for the rest communication. The entire design is to reduce page loads and the amount of data communicated, to allow for a fast and speedy load. It is not framework heavy to allow for people in the future to customise the end page. It is only an example, and not prescribed.
Resources
This stores the favicon.
Rest-API
The Rest-API component provides a template for the REST results. It contains a model that responses from REST backends should provide as well as a javax.rs annotated interface which your project can inherit to guarantee Kagura.js compatibility.